关系型数据库
关系数据库,是建立在关系模型基础上的数据库,借助于集合代数等数学概念和方法来处理数据库中的数据。
现实世界中的各种实体以及实体之间的各种联系均用关系模型来表示。关系模型是由埃德加·科德于1970年首先提出的,并配合“科德十二定律”。现如今虽然对此模型有一些批评意见,但它还是数据存储的传统标准。标准数据查询语言SQL就是一种基于关系数据库的语言,这种语言执行对关系数据库中数据的检索和操作。 关系模型由关系数据结构、关系操作集合、关系完整性约束三部分组成。
简单说,关系型数据库是由多张能互相联接的二维行列表格组成的数据库。
NoSQL
NoSQL(Not Only SQL),泛指非关系型的数据库。
随着互联网Web2.0网站的兴起,传统的关系数据库在应付Web2.0网站,特别是超大规模和高并发的SNS类型的Web2.0纯动态网站已经显得力不从心,暴露了很多难以克服的问题,而非关系型的数据库则由于其本身的特点得到了非常迅速的发展。NoSQL数据库的产生就是为了解决大规模数据集合多重数据种类带来的挑战,尤其是大数据应用难题。
NoSQL数据库的四大分类:
今天我们要说的,便是图形数据库。
图形数据库
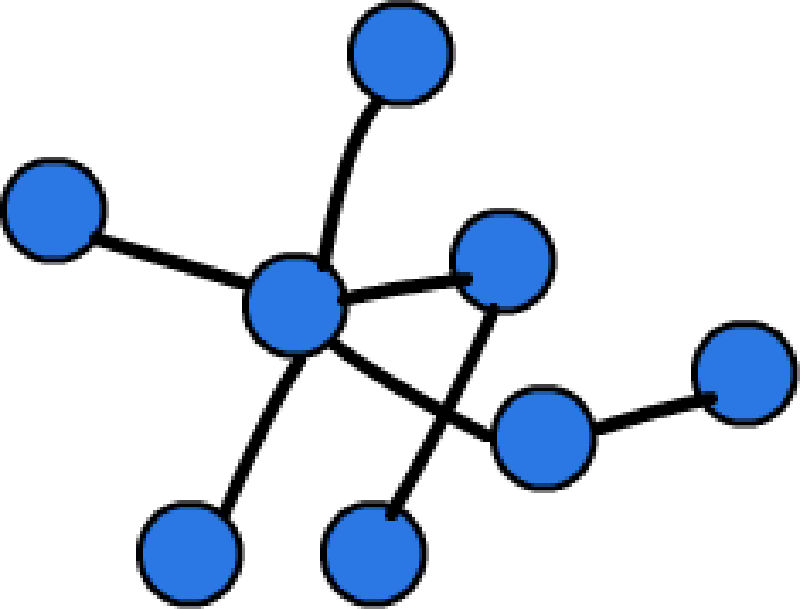
图形数据库是NoSQL数据库的一种类型,它应用图形理论存储实体之间的关系信息。图形数据库是一种非关系型数据库,它应用图形理论存储实体之间的关系信息。最常见例子就是社会网络中人与人之间的关系。关系型数据库用于存储“关系型”数据的效果并不好,其查询复杂、缓慢、超出预期,而图形数据库的独特设计恰恰弥补了这个缺陷。
和其他以列、行或者KV等形式存储数据的数据库不同,图形数据库以节点(Node)和边(Edge)的网络存储所有信息。边表示那些代表对象的节点之间的联系。因为边和节点都可以被描述为对象,开发者可以为其指定属性(Attribute,或者 property)。为边增加方向最终会创建一个属性图,它代表图形数据库中的明确结构。
我们为什么需要图形数据库?
图形数据库可以通过使用操作、所有权和父项关系等来表示实体之间的关联关系。如果实体间的连接或关系是您正在尝试建模的数据的核心,那就适合使用图形数据库。因此,图形数据库对于建模和查询社交网络、推荐引擎、知识图谱、驾驶方向 (路线查找)、业务关系、依赖关系、货物移动等类似项目非常有用。
社交网络
适合采用图形的常见使用案例的一个示例就是社交网络数据。
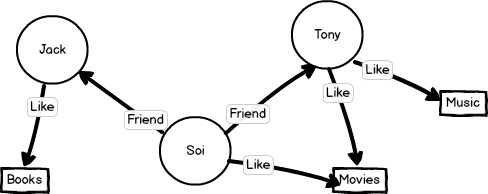
推荐引擎
可以在图形数据库中存储客户兴趣、好友和购买历史等信息类别之间的关系。然后,快速查询它以提出个性化和相关的建议。例如,可以使用高度可用的图形数据库,根据关注相同运动内容且具有类似购买历史记录的其他人购买的产品,向用户提供产品推荐。或者,可以识别有共同好友但还不认识对方的人员,然后提供好友推荐。
知识图谱
利用知识图形,您可以将信息存储在图形模型中,并可以使用图形查询帮助用户更轻松地导航高度关联的数据集。例如,如果用户对 Leonardo da Vinci 创作的 Mona Lisa 感兴趣,您可以帮助他们发现同一艺术家的其他艺术作品或发现在卢浮宫展览的其他作品。
利用知识图谱,您可以将主题信息添加到产品目录,构建和查询复杂的监管规则模型,或者进行一般信息建模 (如维基数据)。
Neo4j
Neo4j是世界领先的图形数据库。 它是一个高性能的图形存储,具有成熟和强大的数据库所需的所有功能,如友好的查询语言和ACID事务。 程序员使用灵活的节点和关系网络结构而不是静态表 - 但享受企业级数据库的所有好处。 对于许多应用程序,与关系数据库相比,Neo4j提供了数量级的性能优势。
安装
老样子,我依旧会适用Docker来进行安装。
1
2
3
4
5
6
| $ docker run -d \
--name neo4j \
-p 7474:7474 -p 7687:7687 \
-v $HOME/neo4j/data:/data \
-v $HOME/neo4j/logs:/logs \
neo4j
|
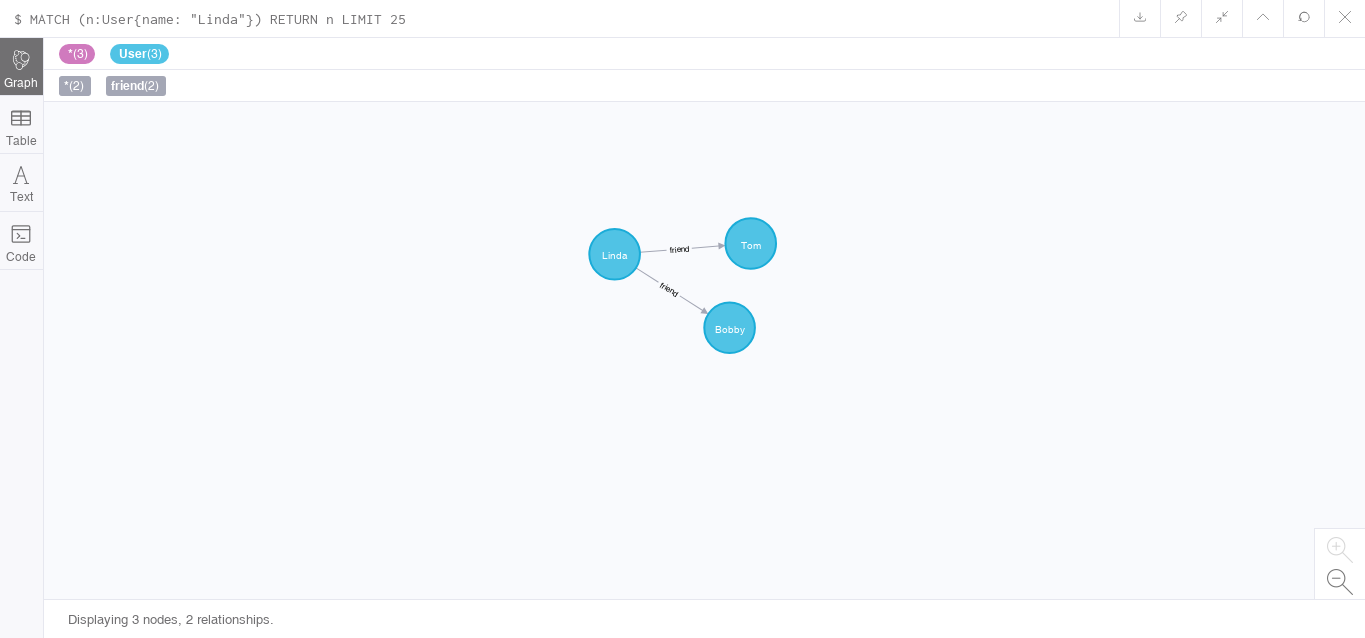
实例
添加依赖
1
2
3
4
| dependencies {
compile("org.neo4j:neo4j-ogm-core:3.1.7")
compile("org.neo4j:neo4j-ogm-http-driver:3.1.7")
}
|
代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
| package team.soi.demo;
import lombok.Getter;
import lombok.Setter;
import org.neo4j.ogm.annotation.GeneratedValue;
import org.neo4j.ogm.annotation.Id;
import org.neo4j.ogm.annotation.NodeEntity;
import org.neo4j.ogm.annotation.Relationship;
import org.neo4j.ogm.config.Configuration;
import org.neo4j.ogm.session.Session;
import org.neo4j.ogm.session.SessionFactory;
import java.io.Serializable;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
public class App {
public static void main(String[] args) {
Configuration configuration = new Configuration.Builder()
.uri("http://neo4j:qazplm@localhost:7474")
.build();
SessionFactory sessionFactory = new SessionFactory(configuration, "team.soi.demo");
Session session = sessionFactory.openSession();
User tom = new User();
tom.setName("Tom");
User bobby = new User();
bobby.setName("Bobby");
User linda = new User();
linda.setName("Linda");
linda.setFriends(Arrays.asList(tom, bobby));
session.save(linda);
}
}
@NodeEntity
@Getter
@Setter
class User implements Serializable {
@Id
@GeneratedValue
private Long id;
private String name;
@Relationship(type = "friend")
private List<User> friends = new ArrayList<>();
}
|
neo4j教程
Dgraph
Dgraph是一个水平可扩展的分布式图形数据库,提供ACID事务,一致的复制和线性化读取。 它是从头开始构建的,用于执行丰富的查询。 作为本机图形数据库,它严格控制数据在磁盘上的排列方式,以优化查询性能和吞吐量,减少磁盘搜索和群集中的网络调用。
Dgraph的目标是提供谷歌生产水平的规模和吞吐量,具有足够低的延迟,可以提供超过数TB的结构化数据的实时用户查询。 Dgraph支持类似GraphQL的查询语法,并通过GRPC和HTTP响应JSON和Protocol Buffers。
安装
由于Dgraph至少要有一个zero和一个server才能使用,所以我们采用docker-compose.yaml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
| version: "3.2"
services:
zero:
image: dgraph/dgraph:latest
volumes:
- type: volume
source: dgraph
target: /dgraph
volume:
nocopy: true
ports:
- 5080:5080
- 6080:6080
restart: on-failure
command: dgraph zero --my=zero:5080
server:
image: dgraph/dgraph:latest
volumes:
- type: volume
source: dgraph
target: /dgraph
volume:
nocopy: true
ports:
- 8080:8080
- 9080:9080
restart: on-failure
command: dgraph alpha --my=server:7080 --lru_mb=2048 --zero=zero:5080
ratel:
image: dgraph/dgraph:latest
volumes:
- type: volume
source: dgraph
target: /dgraph
volume:
nocopy: true
ports:
- 8000:8000
command: dgraph-ratel
volumes:
dgraph:
|
实例
依赖
1
| compile("io.dgraph:dgraph4j:1.7.1")
|
代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
| package team.soi.demo;
import com.google.gson.Gson;
import com.google.gson.annotations.SerializedName;
import com.google.protobuf.ByteString;
import io.dgraph.DgraphClient;
import io.dgraph.DgraphGrpc;
import io.dgraph.DgraphProto;
import io.dgraph.Transaction;
import io.grpc.ManagedChannel;
import io.grpc.ManagedChannelBuilder;
import lombok.Getter;
import lombok.Setter;
import java.io.Serializable;
import java.time.LocalDateTime;
import java.util.*;
public class DgraphApp {
public static void main(String[] args) {
ManagedChannel channel = ManagedChannelBuilder
.forAddress("localhost", 9080)
.usePlaintext()
.build();
DgraphGrpc.DgraphStub stub = DgraphGrpc.newStub(channel);
DgraphClient dgraph = new DgraphClient(stub);
//
dgraph.alter(DgraphProto.Operation.newBuilder().setDropAll(true).build());
Gson gson = new Gson();
Transaction tx = dgraph.newTransaction();
try {
Tag database = new Tag();
database.setName("Database");
Tag graph = new Tag();
graph.setName("Graph");
Category category = new Category();
category.setName("GraphDB");
Post post = new Post();
post.setTitle("Hello dgraph");
post.setDigest("Dgraph demo.");
post.setContent("Hello dgraph,this is a demo.");
post.setViews(0);
post.setCreated(LocalDateTime.now().toString());
post.setTags(Arrays.asList(database, graph));
post.setCategories(Collections.singletonList(category));
String json = gson.toJson(post);
DgraphProto.Mutation mu = DgraphProto.Mutation
.newBuilder()
.setSetJson(ByteString.copyFromUtf8(json))
.build();
tx.mutate(mu);
tx.commit();
} finally {
tx.discard();
}
// query
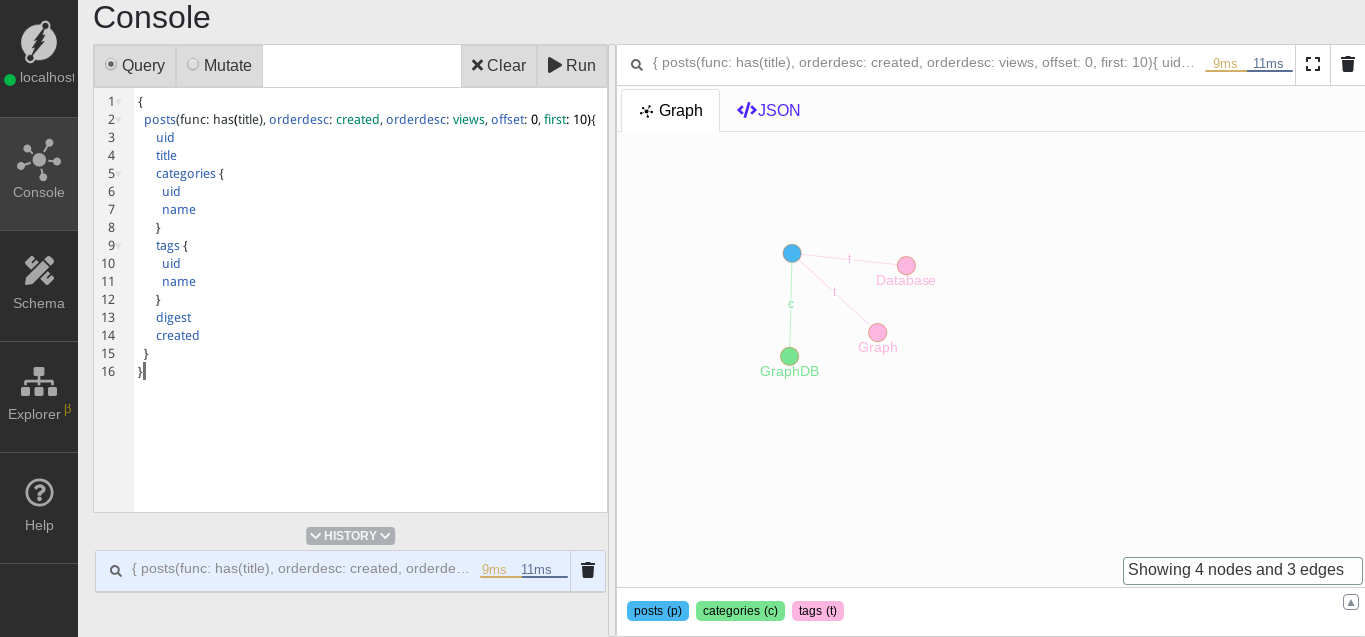
String query = "query posts($offset: int, $count: int){\n" +
"\t\tposts(func: has(title), orderdesc: created, orderdesc: views, offset: $offset, first: $count){\n" +
"\t\t\tuid\n" +
"\t\t\ttitle\n" +
"\t\t\tcategories {\n" +
"\t\t\t\tuid\n" +
"\t\t\t\tname\n" +
"\t\t\t}\n" +
"\t\t\ttags {\n" +
"\t\t\t\tuid\n" +
"\t\t\t\tname\n" +
"\t\t\t}\n" +
"\t\t\tdigest\n" +
"\t\t\tcreated\n" +
"\t\t}\n" +
"\t}";
Map<String, String> vars = new HashMap<>();
vars.put("$offset", "0");
vars.put("$count", "25");
DgraphProto.Response response = dgraph.newReadOnlyTransaction().queryWithVars(query, vars);
Posts posts = gson.fromJson(response.getJson().toStringUtf8(), Posts.class);
System.out.printf("Found hot post: %d\n", posts.getPosts().size());
posts.getPosts().forEach(post -> System.out.println(post.getTitle()));
}
}
@Getter
@Setter
class Posts implements Serializable {
List<Post> posts;
}
@Getter
@Setter
class Post implements Serializable {
@SerializedName("uid")
private String id;
private String title;
private String digest;
private String content;
private String created;
private Integer views;
private List<Tag> tags = new ArrayList<>();
private List<Category> categories = new ArrayList<>();
}
@Getter
@Setter
class Tag implements Serializable {
@SerializedName("uid")
private String id;
private String name;
}
@Setter
@Getter
class Category implements Serializable {
@SerializedName("uid")
private String id;
private String name;
}
|
Dgraph中文文档
结束语
当然,本次知识粗略介绍了下图数据库,如果有时间,后续我应该会找一个场景来实际应用,先挖个坑,后续努力补上 :smile: 。